
Search is one of the pillars of the web, and full-text search is one of the mandatory features that every website needs. But implementing such a feature is complex, and lots of skilled engineers have already thought hard about this topic. So let’s not reinvent the wheel, and use the battle-tested Hibernate Search library.
In this blog post, we are going to learn how to build a simple REST API endpoint in Spring boot with full-text search using Hibernate Search. We will only go through the basics, but Hibernate Search is a feature-rich library with many features going way beyond what we will see in this post. You can check everything that it provides in the official documentation https://docs.jboss.org/hibernate/stable/search/reference/en-US/html_single/#gettingstarted-framework.
Project Bootstrap
The first step is to generate the spring boot project using spring initializr. In this tutorial, We are using the spring CLI via SDKman, but it can easily be done using the web UI https://start.spring.io/ or directly through your IDEA https://www.jetbrains.com/help/idea/spring-boot.html.
To have a walkthrough of how to set up the CLI on your own machine, follow this guide https://docs.spring.io/spring-boot/docs/current/reference/html/getting-started.html#getting-started.installing.cli.sdkman. Once you have installed the CLI , execute this command to generate the project with the necessary dependencies.
spring init --dependencies=web,data-jpa,h2,lombok,validation spring-boot-hibernate-search
We package the following dependencies :
- the web dependency for the REST API.
- the spring data JPA for the data access layer, which uses hibernate as the default Object Relational Mapping tool.
- the h2 library to provide an easy-to-use in-memory embedded database. This type of database is suited for small toy projects such as this one, but it should not be used for any serious project that will be shipped to production at some point.
- Lombok to generate snippets of code through annotation and avoid any boilerplate code
- validation is the Hibernate implementation of the validation API that follows the JSR 380 specification. It allows, among other things, to validate beans using annotation.
Hibernate Search Setup
As with many libraries, Spring Boot provides an easy way to integrate Hibernate Search. We just need to add the required dependencies into the pom.xml file.
<properties>
<hibernate.search.version>6.1.1.Final</hibernate.search.version>
</properties>
...
<dependencies>
...
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm</artifactId>
<version>${hibernate.search.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-lucene</artifactId>
<version>${hibernate.search.version}</version>
</dependency>
</dependencies>
We are using hibernate search 6 which is the most recent version to date, with Lucene as the backend. Lucene is an open-source indexing and search engine library, and the default implementation used by Hibernate Search. We could also use different implementations such as ElasticSearch or OpenSearch.
Defining the data model
The first step is to define the model of the entity on which the search will be done.
As an example, we will use a Plant entity, containing the plant's common name, scientific name, family, and date of creation.
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.hibernate.annotations.NaturalId;
import org.hibernate.search.mapper.pojo.mapping.definition.annotation.FullTextField;
import org.hibernate.search.mapper.pojo.mapping.definition.annotation.Indexed;
import javax.persistence.*;
import java.time.Instant;
@Indexed
@Entity
@Table(name = "plant")
@Getter
@Setter
@ToString
@EqualsAndHashCode
public class Plant {
public Plant() {
this.createdAt = Instant.now();
}
public Plant(String name, String scientificName, String family) {
this.name = name;
this.scientificName = scientificName;
this.family = family;
this.createdAt = Instant.now();
}
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@FullTextField()
@NaturalId()
private String name;
@FullTextField()
@NaturalId()
private String scientificName;
@FullTextField()
private String family;
private Instant createdAt ;
}
Let’s ignore the JPA and Lombok annotations, and focus on the Hibernate Search-related ones.
First, the @Index annotation indicates to Hibernate Search that we want to index this entity in order to apply search operation on it.
Second, we annotate the fields we want to search on with the @FullTextField annotation. This annotation works only for string fields, but others exist for fields of different types.
And ... that’s it! It is as simple as that for a simple case such as ours!
But you can do much more with what the library provides, such as using conditional indexing or tweaking indexing coordination. Once again, check out the official documentation if you want to know more.
Defining the data layer
We now need to define our data layer handling the interactions with the database.
We use Spring Data repositories which build an abstraction around the Hibernate implementation of JPA. It is provided in the spring-boot-starter-data-jpa dependency added previously.
For a basic use case requiring only CRUD operations, we can define a simple repository for the Plant entity and extends the JpaRepository interface directly.
But this is not enough for full-text search. In our case, we would like to add the search features to all repositories we define. For that, we need to add custom methods to the JpaRepository interface, or any interface extending the base Repository interface.
This way, we declare those methods only once and make them available for every repository of every entity of our project.
Let’s see how we can do such a thing.
First, we need to create a new generic interface that extends the JpaRepository interface.
@NoRepositoryBean
public interface SearchRepository<T, ID extends Serializable> extends JpaRepository<T, ID> {
List<T> searchBy(String text, int limit, String... fields);
}
We declare the searchBy function that will be used for full-text search operations.
The @NoRepositoryBean annotation tells spring that this repository interface should not be instantiated like any other bean with the @Repository annotation.
We use this annotation because the purpose of this interface is not to be used directly, but to be implemented by other repositories.
We also need to create the implementation for this interface.
@Transactional
public class SearchRepositoryImpl<T, ID extends Serializable> extends SimpleJpaRepository<T, ID>
implements SearchRepository<T, ID> {
private final EntityManager entityManager;
public SearchRepositoryImpl(Class<T> domainClass, EntityManager entityManager) {
super(domainClass, entityManager);
this.entityManager = entityManager;
}
public SearchRepositoryImpl(
JpaEntityInformation<T, ID> entityInformation, EntityManager entityManager) {
super(entityInformation, entityManager);
this.entityManager = entityManager;
}
@Override
public List<T> searchBy(String text, int limit, String... fields) {
SearchResult<T> result = getSearchResult(text, limit, fields);
return result.hits();
}
private SearchResult<T> getSearchResult(String text, int limit, String[] fields) {
SearchSession searchSession = Search.session(entityManager);
SearchResult<T> result =
searchSession
.search(getDomainClass())
.where(f -> f.match().fields(fields).matching(text).fuzzy(2))
.fetch(limit);
return result;
}
}
The searchBy method implementation is where Hibernate Search is used.
The following arguments are passed:
- text: text to search for
- limit: maximum number of elements to search for
- fields: name of all the fields to search on
We make use of java varargs to pass all the fields we want to search on.
Here, we use a simple fuzzy algorithm as the full-text matching algorithm, but we can easily make more complex searches using custom analyzers.
From now on, repositories requiring full-text-search just have to implement the SearchRepository interface instead of the standard JpaRepository interface provided by Spring.
And this is exactly what we are doing for the Plant entity.
package com.mozen.springboothibernatesearch.repository;
import com.mozen.springboothibernatesearch.model.Plant;
import org.springframework.stereotype.Repository;
@Repository
public interface PlantRepository extends SearchRepository<Plant, Long> {
}
As you can see, all implementation is already done, and we just need to implement the previously created SearchRepository interface to get access to the implementation defined in the SearchRepositoryImpl class.
The final step is to indicate to Spring to detect Jpa Repositories using the SearchRepositoryImpl as the base class.
package com.mozen.springboothibernatesearch;
import com.mozen.springboothibernatesearch.repository.SearchRepositoryImpl;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@Configuration
@EnableJpaRepositories(repositoryBaseClass = SearchRepositoryImpl.class)
public class ApplicationConfiguration {
}
Note that because we do not specify any base package to search into, Spring will use the package where this Configuration is defined as the base package.
Defining the business layer
Let’s now create the business code using the data layer we’ve just defined, by declaring a service.
package com.mozen.springboothibernatesearch.service;
import com.mozen.springboothibernatesearch.model.Plant;
import com.mozen.springboothibernatesearch.repository.PlantRepository;
import org.springframework.stereotype.Service;
import java.util.Arrays;
import java.util.List;
@Service
public class PlantService {
private PlantRepository plantRepository;
private static final List<String> SEARCHABLE_FIELDS = Arrays.asList("name","scientificName","family");
public PlantService(PlantRepository plantRepository) {
this.plantRepository = plantRepository;
}
public List<Plant> searchPlants(String text, List<String> fields, int limit) {
List<String> fieldsToSearchBy = fields.isEmpty() ? SEARCHABLE_FIELDS : fields;
boolean containsInvalidField = fieldsToSearchBy.stream(). anyMatch(f -> !SEARCHABLE_FIELDS.contains(f));
if(containsInvalidField) {
throw new IllegalArgumentException();
}
return plantRepository.searchBy(
text, limit, fieldsToSearchBy.toArray(new String[0]));
}
}
We tell Spring that this bean is part of the business layer of the application.
It contains a searchPlant function that forwards the call to the searchBy function of the SearchRepository.
Before forwarding the call, it validates the provided fields.
Those fields are whitelisted to check that the search will be made only against the desired fields, which are the ones we have annotated with @FullTextField annotation earlier.
We throw an IllegalArgumentException if one of the provided fields is not part of the whitelisted ones. The exception is not handled for the sake of simplicity, but it should be handled properly using one of the many ways provided by spring to handle exceptions.
Defining the web layer
The next step is to define the REST API to receive the HTTP request coming from client applications.
package com.mozen.springboothibernatesearch.controller;
import com.mozen.springboothibernatesearch.model.Plant;
import com.mozen.springboothibernatesearch.model.SearchRequestDTO;
import com.mozen.springboothibernatesearch.service.PlantService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/plant")
public class PlantController {
private PlantService plantService;
public PlantController(PlantService plantService) {
this.plantService = plantService;
}
@GetMapping("/search")
public List<Plant> searchPlants(SearchRequestDTO searchRequestDTO) {
log.info("Request for plant search received with data : " + searchRequestDTO);
return plantService.searchPlants(searchRequestDTO.getText(), searchRequestDTO.getFields(), searchRequestDTO.getLimit());
}
}
We use a basic Rest controller with a single GET mapping. Before forwarding the call to the business layer, we log the event to trace the reception of the request to ease the monitoring of the application. It receives the search request using a SearchRequestDTO
package com.mozen.springboothibernatesearch.model;
import lombok.Data;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotBlank;
import java.util.ArrayList;
import java.util.List;
@Data
public class SearchRequestDTO {
@NotBlank
private String text;
private List<String> fields = new ArrayList<>();
@Min(1)
private int limit;
}
It is a simple POJO containing the parameters used for the search. Once again, we use Javax Bean Validation annotations to ensure the request is valid, as well as Lombok @Data annotation to generate boilerplate code (Getters, Setters, toString(), ...).
Note that by using a POJO as a single argument for the REST API endpoint, we expect the client to send those parameters as Request Parameter inside the HTTP request.
Indexing the data
Finally, for Lucene to be able to search through the data, it needs to be indexed.
At runtime, the index is automatically managed by Hibernate, by applying the change each time an operation is executed through Hibernate ORM such as creating or deleting an Entity. However, We still need to initialize the index for data already stored in the database if any.
For that purpose, we need to add some configurations inside the application.yml file:
server:
port: 9000
spring:
datasource:
url: jdbc:h2:mem:mydb
username: mozen
password: password
jpa:
open-in-view: false
properties:
hibernate:
search:
backend:
type: lucene
directory.root: ./data/index
We indicate the root directory of where the Lucene index is stored. Here, we choose to place it directly in the project folder, but this directory should be carefully chosen when running in production, depending on where your application is deployed.
We also create a component to wrap all operations related to the Lucene index.
package com.mozen.springboothibernatesearch.index;
import org.hibernate.search.mapper.orm.Search;
import org.hibernate.search.mapper.orm.massindexing.MassIndexer;
import org.hibernate.search.mapper.orm.session.SearchSession;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import javax.persistence.EntityManager;
@Transactional
@Component
public class Indexer {
private EntityManager entityManager;
private static final int THREAD_NUMBER = 4;
public Indexer(EntityManager entityManager) {
this.entityManager = entityManager;
}
public void indexPersistedData(String indexClassName) throws IndexException {
try {
SearchSession searchSession = Search.session(entityManager);
Class<?> classToIndex = Class.forName(indexClassName);
MassIndexer indexer =
searchSession
.massIndexer(classToIndex)
.threadsToLoadObjects(THREAD_NUMBER);
indexer.startAndWait();
} catch (ClassNotFoundException e) {
throw new IndexException("Invalid class " + indexClassName, e);
} catch (InterruptedException e) {
throw new IndexException("Index Interrupted", e);
}
}
}
For our simple demo application, we only declare a function that builds the index for a given Class using the specified amount of threads in the process.
We now need to call that function passing the previously defined Plant class as an argument.
For that purpose, we could also create a new REST Controller containing an endpoint to trigger the indexing via an HTTP request, to be able to rebuild the index at will.
But for the sake of this article, we are just going to use an ApplicationRunner that will be called at each startup.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public ApplicationRunner buildIndex(Indexer indexer) throws Exception {
return (ApplicationArguments args) -> {
indexer.indexPersistedData("com.mozen.springboothibernatesearch.model.Plant");
};
}
}
We define the Bean directly in the main Application class.
The buildIndex method takes the Indexer as an argument through dependency injection. The method is executed during the application startup, right after the context initialization, and before the startup of the spring boot application.
Putting it all together
Let’s first initialize the sample data.
package com.mozen.springboothibernatesearch;
import com.mozen.springboothibernatesearch.index.Indexer;
import com.mozen.springboothibernatesearch.model.Plant;
import com.mozen.springboothibernatesearch.repository.PlantRepository;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import java.util.Arrays;
import java.util.List;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public ApplicationRunner initializeData(PlantRepository plantRepository) throws Exception {
return (ApplicationArguments args) -> {
List<Plant> plants = Arrays.asList(
new Plant("subalpine fir", "abies lasiocarpa", "pinaceae"),
new Plant("sour cherry", "prunus cerasus", "rosaceae"),
new Plant("asian pear", "pyrus pyrifolia", "rosaceae"),
new Plant("chinese witch hazel", "hamamelis mollis", "hamamelidaceae"),
new Plant("silver maple", "acer saccharinum", "sapindaceae"),
new Plant("cucumber tree", "magnolia acuminata", "magnoliaceae"),
new Plant("korean rhododendron", "rhododendron mucronulatum", "ericaceae"),
new Plant("water lettuce", "pistia", "araceae"),
new Plant("sessile oak", "quercus petraea", "fagaceae"),
new Plant("common fig", "ficus carica", "moraceae")
);
plantRepository.saveAll(plants);
};
}
@Bean
public ApplicationRunner buildIndex(Indexer indexer) throws Exception {
return (ApplicationArguments args) -> {
indexer.indexPersistedData("com.mozen.springboothibernatesearch.model.Plant");
};
}
}
We extend the main Application class with a second Bean declaration. It will be run in the same way as the first one, during the application startup.
Note that we did not declare the data SQL schema anywhere. Because our database is an embedded database, the property spring.jpa.hibernate.ddl-auto is set to create-drop by default, and our database schema is automatically generated, which is neat for simple applications such as this one.
Now, let’s test, by first starting our application.
mvn spring-boot:run
There are multiples ways to test the search endpoint.
We can use the API Platform Postman :
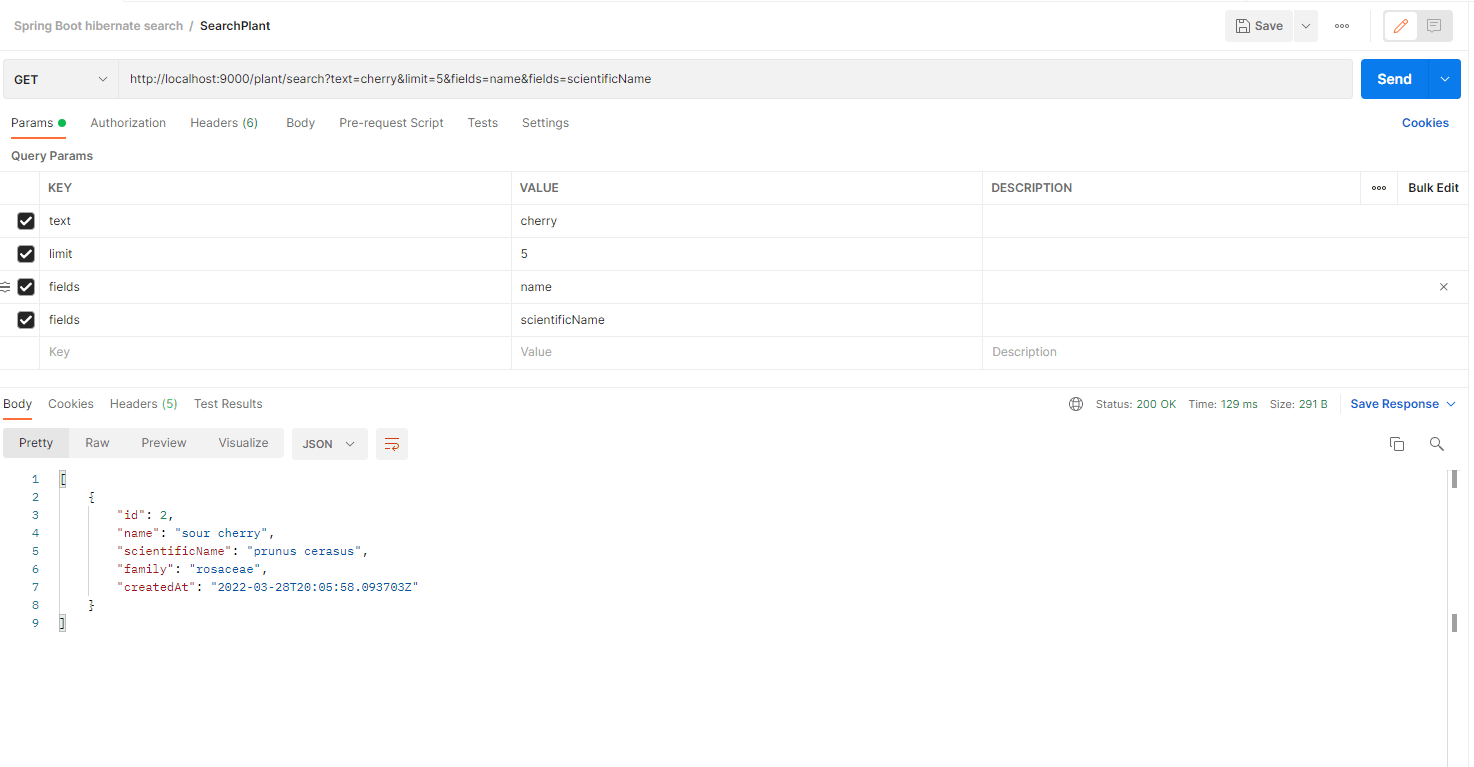
Or we can use a simple cUrl command with the required parameters :
// Search in all fields
curl -X GET 'http://localhost:9000/plant/search?text=cherry&limit=5'
// Search only in specified fields
curl -X GET 'http://localhost:9000/plant/search?text=sian p&limit=5&fields=name&fields=scientificName'
And that’s it! We now have full-text-search implemented through an HTTP endpoint.
As I’ve said many times during this blog, Hibernate Search provides much more features, and we’ve just scratched the surface here.
I will publish more blog posts to address more advanced topics soon.
You can access the demo project for this blog post here https://github.com/Mozenn/spring-boot-hibernate-search.